ABACUS: Dynamic Function Placement for Data-Intensive Cluster Computing
Problem
Effectively utilizing cluster resources is a difficult problem for distributed applications. Since remote communication is much more expensive than local communication, the performance of these applications is sensitive to the distribution of their functions across the network. As a result, using cluster resources effectively requires not only load balancing, but also proper partitioning of functionality among nodes. While software engineering techniques (e.g., modularity and object orientation) have given us the ability to partition applications into a set of interacting objects, we do not yet have solid techniques for determining where in the cluster each of these functions should run, and deployed systems continue to rely on complex manual decisions made by programmers and system administrators.
Optimal function placement in a cluster is difficult because the right answer is usually, "it depends." Specifically, it depends on a variety of cluster characteristics (e.g., communication bandwidth between nodes, relative processor speeds among nodes) and workload characteristics (e.g., bytes moved among functions, instructions executed by each function). Some are basic hardware characteristics that only change when something fails or is upgraded, and thus are relatively constant for a given system. Other characteristics cannot be determined until application invocation time because they depend on input parameters. Worst of all, many change at run-time due to phase changes in application behavior or competition between concurrent applications over shared resources. Hence, any "one system fits all" solution will cause suboptimal, and in some cases disastrous, performance.
Approach
In this project, we focus on an important class of applications for which clusters are very appealing: data-intensive applications that selectively filter, mine, sort, or otherwise manipulate large data sets. Such applications benefit from the ability to spread their data-parallel computations across source/sink servers, exploiting the servers' computational resources and reducing the required network bandwidth. Effective function partitioning for these data-intensive applications will become even more important as processing power becomes ubiquitous, reaching devices and network-attached appliances.
We observe that these data-intensive applications have characteristics that simplify the tasks involved with dynamic function placement. Specifically, these applications all process and move significant amounts of data, enabling a monitoring system to quickly learn about the most important inter-object communication patterns and per-object resource requirements. This information allows the run-time system to rapidly identify functions that should be moved to reduce communication overheads or resource contention.
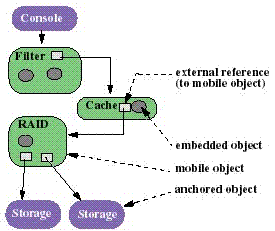
We designed and implemented a prototype system, called Abacus, which automates the placement of the objects in data-intensive applications and filesystems between clients and servers. Abacus consists of a programming model and a run-time system. The Abacus programming model encourages the programmer to compose data-intensive applications from small, functionally independent components or objects. These mobile objects provide explicit methods which checkpoint and restore their state during migration. Figure 1 represents a sketch of objects in Abacus.
The Abacus run-time system consists of (i) a migration and location-transparent invocation component; and (ii) a resource monitoring and management component, as shown in Figure 2. The first component is responsible for the creation of location-transparent references to mobile objects, for the redirection of method invocations in the face of object migrations, and for enacting object migrations.
The resource monitoring and management component uses the notifications to collect statistics about bytes moved between objects and about the resources used by active objects (e.g., amount of memory allocated, and number of instructions executed per byte processed). Moreover, this component monitors the availability of resources throughout the cluster (e.g., node load and available bandwidth on network links). An analytic model is used to predict the performance benefit of moving to an alternative placement. The model also takes into account the cost of migration - the time needed to acquiesce and checkpoint an object, transfer its state to the target node, and restore it on that node. Using this analytic model, the component arrives at the placement with the best net benefit.
 |
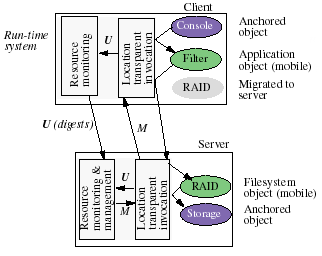 |
Figure 1. Objects in Abacus. Objects in Abacus have private state that is only accessible through their exported interface. The private state can contain references to embedded objects, or to external objects. Objects can be either anchored or mobile. Anchored objects include storage objects which provide persistent storage. A part of each application is usually anchored to the node where the application starts. The console is usually not data-intensive but serves for initialization and user/system interface functions. |
Figure 2. The Abacus run-time system. This example shows a filter accessing a striped file. Functionality is partitioned into objects. Inter-object method invocations are transparently redirected by the location transparent invocation component of the Abacus run-time, which also updates the resource monitoring component on each procedure call and return from a mobile object (arrows labeled "U"). Clients periodically send digests of the statistics to the server. Resource managers at the server collect the relevant statistics and initiate migration decisions ("M").
|
Preliminary Results
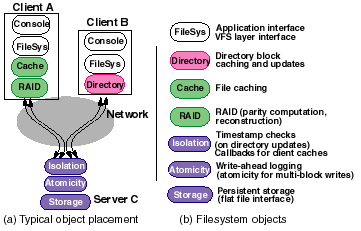
Figure 3 below depicts the architecture of an object-based filesystem that we built on top of Abacus. Figure 4 depicts possible placements for RAID objects in our environment.
 |
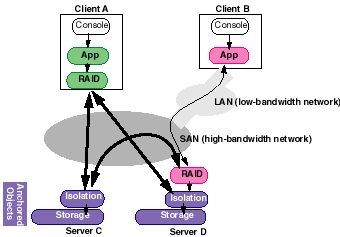 |
Figure 3. This figure shows the architecture of an object-based distributed filesystem built for Abacus. Files are bound to an object stack. |
Figure 4. RAID example. This figure depicts different placements for the RAID object as the client-server network bandwidth varies. |
Our environment consists of two networks, a switched 100Mbps Ethernet,
which we refer to as the SAN (server-area network) and a shared 10Mbps
segment, which we refer to as the LAN (local-area network). All four
storage servers are directly connected to the SAN. Four of the eight
clients, are connected to the SAN (called SAN clients), and the other
four clients reside on the LAN (the LAN clients). The LAN is bridged
to the SAN via a 10Mbps link. Clients and servers are standard PCs running
RedHat Linux 5.2 on 300MHz Pentium II processors.
Figure 5 through Figure 8 below show the performance of applications when function is statically placed at the client or at the server, and when it is dynamically placed by Abacus after being started on the client.
 |
 |
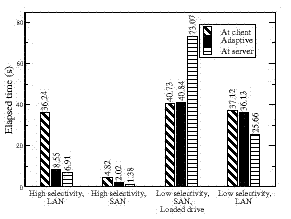
| Figure 5. Filter benchmark. Executing a filter (a program such as grep which returns a portion of the data it reads) at the storage server is advantageous in all but the third configuration, in which the filter is computationally expensive and runs faster on the more resourceful client. |
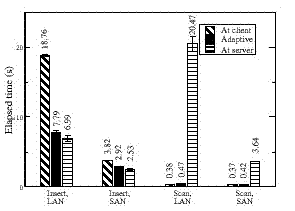
Figure 6. Cache benchmark. The figure shows that client-side caching is essential for workloads exhibiting reuse (Scan), but causes pathological performance when inserting small records (Insert) because of installation reads. |
 |
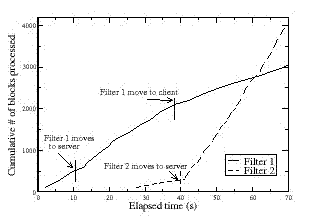 |
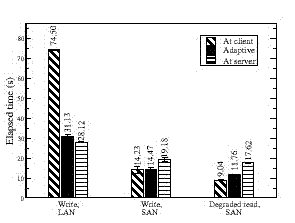
Figure 7. RAID benchmark. This figures shows that contention on the server's CPU resources make client-based RAID more appropriate, except in the LAN case, where the network is the bottleneck. Abacus selects the best placement by making the proper trade-off between faster client-side processing and increased network stall time due to client-side execution. |
Figure 8. Concurrent filter benchmark. This figure plots the cumulative number of blocks searched by two filters versus elapsed time. In this experiment, the server's memory is artificially constrained so that only one filter can execute at the server. After the more selective Filter 2 begins running, Abacus' online placement algorithm correctly chooses to move the less selective Filter 1 back to the client in order to allow Filter 2 to be executed at the server. |
Our initial experiments demonstrate that Abacus can effectively adapt to variations in network topology, application cache access pattern, application data reduction (filter selectivity), contention over shared data, significant changes in application behavior at run-time, as well as dynamic competition from concurrent applications over shared server resources. Our preliminary results are quite promising; Abacus often improved application response time over 6X. Under all these experiments, Abacus selects the best placement for each function, "correcting" placement when function was initially started on the "wrong" node. Under more complex scenarios, Abacus outperforms experiments in which function was statically placed at invocation time, converging to within 70% of the maximum achievable performance. Furthermore, Abacus adapts placement without knowledge of the semantics implemented by the objects. The adaptation is based only on black-box monitoring of the object and the bytes moved between objects.
Summary
Effectively utilizing cluster resources is a difficult problem for distributed applications. Since remote communication is much more expensive than local communication, the performance of these applications is sensitive to the distribution of their functions across the network. Optimal function placement in a cluster is difficult because it depends on several characteristics, many of which vary at run-time.
Black-box monitoring of application objects, in combination with an intuitive object-based mildly-constrained programming model can provide sufficient support for automatic partititioning of filesystem and application function in data-intensive cluster computing. We believe that this automatic approach will help reduce the exorbitant management costs of clusters.
Publications
- Easing the Management of Data-parallel Systems via Adaptation Petrou, D., Amiri, K., Ganger, G.R. and Gibson, G.A. Appears in the
Proceedings of the 9th ACM SIGOPS European Workshop, Kolding, Denmark,
September 17-20, 2000.
Abstract / Postscript [622K] / PDF [122k]
- Dynamic Function Placement for Data-intensive Cluster Computing. Amiri, K., Petrou, D., Ganger, G.R. and Gibson, G.A. Proceedings of
the USENIX Annual Technical Conference, San Diego, CA, June 2000.
Supercedes CMU SCS Technical Report CMU-CS-99-140, June 1999.
Abstract / Postscript [386K] / PDF [182k]
- Dynamic Function Placement in Active Storage Clusters. Amiri,
K., Petrou, D., Ganger, G.R. and Gibson, G.A. CMU SCS Technical Report
CMU-CS-99-140, June 1999. Superceded by USENIX Annual Technical Conference,
San Diego, CA, June 2000.
Abstract / Postscript [730K] / PDF [220K]
- SOSP '99 Poster.
Acknowledgements
We thank the members and companies of the PDL Consortium: Amazon, Google, Hitachi Ltd., Honda, Intel Corporation, IBM, Meta, Microsoft Research, Oracle Corporation, Pure Storage, Salesforce, Samsung Semiconductor Inc., Two Sigma, and Western Digital for their interest, insights, feedback, and support.